

Several years ago, when I was working as a structural engineer, my boss described the hypothetical back-and-forth workflow between a Revit model and a structural model as the “Holy Grail” of workflows. In other words, it’s a workflow that is highly coveted yet practically unattainable. There are decent tools that help you go one way to create a Revit model based on a structural model (or the other way around) but keeping the two models synced up with one another is a problem that is orders of magnitude more complicated.
And yet this is exactly the issue that the Speckle CSI connector wants to solve. Softwares like Revit and ETABS are essentially storehouses for data that you create in the software. If you’ve already made changes to your model in Revit, then why should you have to model it again in ETABS?
The data that you want to create already exists.
Therefore, one of the goals of the ETABS connector is to enable users to duplicate the results of their work instead of having to duplicate the work itself.
From Theory to Practice: Applied Round Tripping
This workflow is something that is referred to as “round-tripping”: the process of taking an element in application A, sending it to one or more different applications, and then receiving the same object back in application A with updated properties.
This idea sounds good in theory, but in reality, this type of round-tripping doesn’t exist: elements undergo permanent transformations when they are received into a new host application.
Some element data is lost and/or gained, and thus the element becomes an entirely new element that just happens to have some similar properties as the original.
Enabling The Holy Grail of Workflows, Without The Tripping
The workflow described earlier is legitimate and would save structural engineers a lot of time in their day-to-day work. How do we enable this bidirectional workflow between ETABS and Revit? With the recent release of the Speckle ETABS connector version 2.12, we’ve done that!
Let's take a look at how it works:
Try It Out Now!
::: tip
What are you waiting for? Install the Revit and ETABS connectors now!
:::
If you are curious about how it works under the hood, a more detailed explanation follows below - beware, it's not for the light hearted 🙂
Tracking Elements Through Different Software
Have you ever wondered why many Speckle objects have this “applicationId” field?
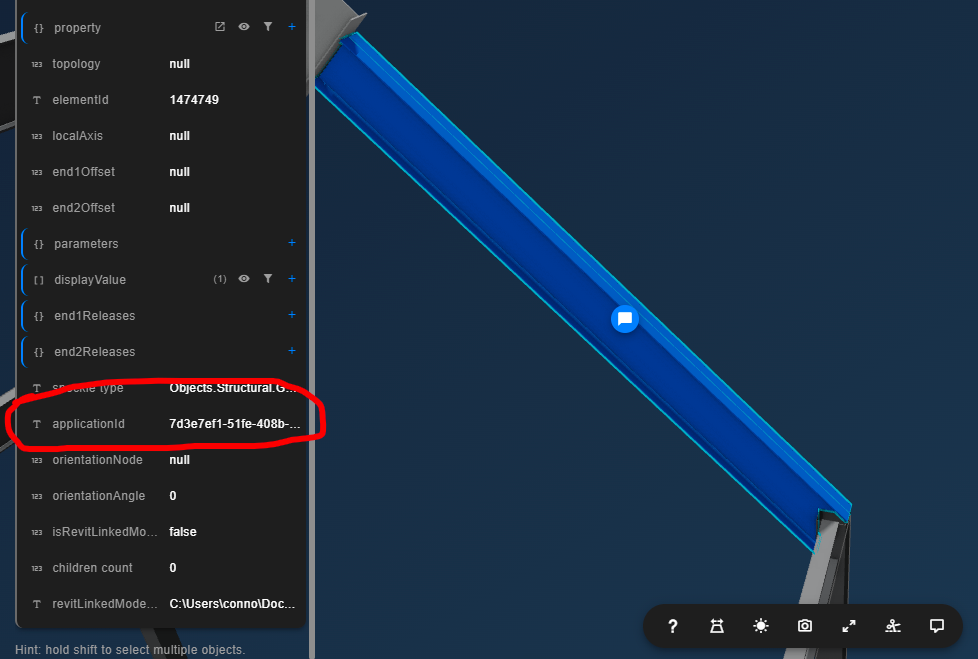
Most programs track all the elements that are modeled in that application with unique identifiers that are random combinations of letters and numbers. Specifically, many of these IDs are stored as GUIDs which are 128-bit text strings, although some programs make things difficult by making their IDs longer than this (thank you, Revit). In an ideal world where all programs could communicate losslessly with each other, this ID value would be the same across applications for every element that represented the same element of a future structure. However, in the real world, all of these IDs are different, so we need to track the different Ids across multiple applications.
Current Implementation
In the tutorial video, I talk about how things work between Revit and ETABS. This implementation is similar for many other connectors, but not all of them. When an element is sent to Speckle from Revit and is then received in ETABS, Speckle will create a link between the original Revit ID for the element and the ETABS ID. The Speckle connector will then save all of these links in a list to be referenced later.
If changes are made in Revit, and the data is re-received in ETABS, the ETABS connector will search the list of ID links to see if it recognizes the incoming Revit ID. If there is an existing link found, then the connector will retrieve the linked ID and try to update the existing element in the model that has the retrieved ID. This is the one-way type of workflow that is very reliable in Speckle.
When you want to send data back to Revit, you enter a two-way workflow that is a bit more unpredictable. Many of the Speckle connectors don’t handle this type of workflow. A popular one is Revit ↔ Rhino. When a wall is sent from Revit to Rhino, it becomes a mesh in Rhino. The one-way workflow will still work on updating the wall in Rhino, but the wall can’t be sent back to Revit to be updated because it no longer has a lot of the properties needed to be a wall (baseLine, height, thickness, etc.).
However, we’re able to enable this specific workflow because the elements in ETABS and Revit have similar enough properties (baseLine, type/profile, material, etc.). The way that we’re enabling this is very simple.
When sending from ETABS to Speckle, each element ID is checked against the existing list of ID links. If the element had a particular applicationId when it was received into ETABS from Speckle, then it gets sent back to Speckle with the same applicationId that it came in with. This is a bit counter-intuitive because it means that the “applicationId” property for an element from ETABS may actually be the ID of a Revit element. When this element is received in Revit, the connector will find that there is an existing element that has the same applicationId as the incoming element, and the Revit connector will attempt to update that element.
Limitations
There are some minor limitations with our current updating process. The first one is that we are misusing the applicationId property. There is Speckle documentation that defines this property as the ID of the element in its host application. However, when we change this value during the send operation from ETABS, this is no longer the case. This is an additional complexity that may not be a big deal on its own but can quickly stack on top of other complexities to make Speckle much more difficult to use. For example, a developer may build something on top of Speckle, which depends on this property corresponding to the element’s applicationId in ETABS, and then that wouldn’t work. Adding too much complexity and undocumented behavior can make external development and contributions extremely frustrating.
Another limitation of this approach is that it can’t be implemented by every connector. This again leads to additional complexity in Speckle. Not only does it mean you need to understand how multiple connectors implement functionality, but it also makes it hard to abstract shared functionality. This leads to more code that needs to be maintained.
Future Considerations
We are actively looking to create a Speckle-wide implementation of this functionality that can work the same way across all Speckle connectors, therefore reducing the complexity of Speckle overall. You won’t need to worry about this change because the behavior of the connector will be the same.
We are considering, along with the applicationId property, that most elements would have an “originalAppID” list where we append every new applicationId to a ledger that belongs to the element and keeps track of the object history that way.