

By automating builds and deployments, we’re able to ship releases faster to focus on the features that matter to you. Our pipelines allow us to create a new release to any of our Connectors in a few minutes. This blog post covers the different ways we do so across our .NET-based desktop Connectors, including an in-depth description of Speckle’s desktop layers and infrastructure.
The Big Picture
The .NET side of Speckle is structured in different parts or “layers”:
Corelayer:
You can think of the Core layer as the most generic and important part of Speckle. This is the layer in charge of communicating with the Server (through our GraphQL and REST endpoints), as well as serialisation/deserialisation of objects, and contains our most basic object implementation: the Base object.
Objectslayer:
This layer is in charge of defining the schema of all Speckle objects (i.e. their shape). Here’s where you’ll find all the common geometric elements (such as lines, meshes…) but also higher-level elements such as BIM (walls, beams…) and application-specific elements (RevitWall, ArchicadWall…).
Desktop User Interfacelayer (DUI):
This layer contains our shared User Interface (UI), allowing us to reutilize the UI code across different applications. This is the main interaction point for most of our Connector users; Rhino, Revit, AutoCAD… use DUI as their main interface, but this layer is optional.
::: tip
These 3 layers are all platform-agnostic, meaning we can use them in any application of choice and represent the most central part of Speckle.
:::
From here, implementations become “application-specific”:
Object Converterslayer:
Once the objects are defined in a “platform-agnostic” way, it is necessary to define how to convert a specific object from an application (i.e. Revit) into its “Speckle representation” and vice-versa. This is what we call the ToNative and ToSpeckle conversions. At this point is where we start interfacing with the specific application APIs and SDKs.
A converter .dll must be created for every application and every version of that application that we want to target. This leads to multiple projects being needed with different dependency versions.
Some examples include:
- Rhino: ConverterRhino6, ConverterRhino7…
- Revit: Converter2019, ConverterRevit2020, ConverterRevit2021….
The list gets more significant as we support 25 applications at the time I’m writing this. This strategy allows us to tailor each converter to its specific application and version, adding support or removing support of features as needed.
Application Connectorslayer:
This layer is where all of our Connectors live. What we call a Connector is just a plugin for a specific application that uses Core, Objects, a specific Converter and (sometimes) the DUI to allow users to work on specific workflows in Speckle.
This is where you’ll find the logic for reading/writing information, selecting objects, filtering, updating… allowing each application to tailor to the way it works.
In general, for each Connector that targets a specific application, we will have a corresponding Converter for said application, both using the same dependency versions. As you probably know, vendors release new versions of their software on a yearly basis (approximately), which means our Connectors and Converters need to be capable of supporting multiple versions.
Infrastructure
Of course, this only covers the application code but doesn’t really go into how you deploy this to a user who doesn’t know anything about C#, compiling, .dll files, etc.
Stack
As each target application requires different target frameworks, each application may target a different version (from .NetFramework v4.6.2 to .Net7.0). In addition, some of our target applications support both Mac and Windows.
Installers
To deliver the Connectors as usable plugins for each application, it is necessary that we ship each one in the form of an installer, which will be in charge of copying over all the .dll files to their appropriate folders, setting the correct registry keys and other actions to register the plugin.
For the sake of simplicity, we decided to opt for a single installer for each application we support, leading to automatic version installs. This reduces the number of installers we actually have to build, as well as the number of clicks a user needs to do to set up their Speckle account.
The installer for Rhino will install the Speckle Connector for Rhino 6 and Rhino 7, same applies to the majority of the connectors. Since we build Connectors for multiple platforms (Mac and Windows), we have two distinct installer strategies.
- For Windows, we use
InnoSetup. It’s quite old but continues to do the trick and is one of the best options out there (that we’ve found, at least…). - For Mac, we have developed our own simple install/uninstall logic in .NEt Core that we build as an executable.
Certificates
Speckle is a trusted provider because we use our own certificates to validate everything that is shipped, ensuring no modification has been made by a malicious actor.
The process to do this is different in Mac and Windows:
- For Windows, we opted for DigiCert Signing certificate.
- For Mac, we have Apple Developer certificates that are used to sign our releases, which is only necessary for The Manager for Speckle.
::: tip
Shipping your software without signing may lead to users being unable to run it or worrying alert messages, depending on their company’s security stance (or their own…).
:::
Deployment
The resulting installer executables need to be stored somewhere to allow users to download them. We do so in an s3-like bucket. We developed our own tool (Manager.Feed) that simplifies the process of uploading installers and keeping track of their versions. We simply run a command in our CI script and Speckle will deal with the whole process. This results in a new file entry (the feed) for the current installer, holding all the additional information necessary (i.e. operating system, release date, version, architecture, target connector…).
Our CI/CD Pipeline
You can imagine that building all these layers, installers, setting up certificates, signing, etc. is no fun for a human to be doing (I can vouch for it… it is not!), especially as we release new versions every 4 to 6 weeks.
Thankfully, it’s common practice to use Continuous Integration / Continuous Deployment (CI/CD) services to do all the hard work automatically. These are based on a configured set of steps defined on a file (usually, yaml) creating what is referred to as a “pipeline”.
At Speckle, we're using CircleCI but there are other great alternatives out there.
Our pipeline has two main jobs:
- Build and test all the different layers (Core, Objects, DUI, Connectors). This should happen for every commit on any branch that has a PR open in our Repo.
- Build, test, and deploy. Same steps as our Build job, in addition deploying the installers to our cloud storage.
Our pipeline has several requirements:
- It must reflect as much as possible the layers we introduced previously to reduce duplication of jobs
- It needs to contain sensitive information (such as Certificates, API keys, etc…) that must not be shared with the outside world (for obvious security reasons)
- It should also allow external collaborators to make PRs and know if their changes lead to any build errors while keeping them from accessing any sensitive data
- It should only build what’s necessary. A change in the Rhino Connector or its conversions may only trigger a build for Rhino, but a change in
CoreorObjects(shared by all Connectors) should trigger a complete build of everything.
To achieve all this, we’ve made use of CircleCI’s “dynamic config” feature, which allows us to split the CI run in two steps:

- A setup, that is in charge of finding what projects need building based on code changes, and building a new CI configuration file dynamically, to be used in a particular run.
- A build, that uses the dynamically generated configuration in the setup step.
::: tip
The setup is key as it allowed us to create a Python script that, based on some input files, will generate the necessary CircleCI configuration file dependent on the different requirements as well as the actual changes in the code.
:::
Keeping An Eye On Changes
Path diffing
In order to determine what has changed in our code, and by extension, what needs building, we leverage a CircleCI orb called circleci/path-filtering, which takes a set of RegEx expressions and returns a json file with some boolean values. This json file will be used by our python script to add the necessary jobs.

Resulting on a json like this 👇🏼 Depending on the Connector that needs building, the value would be true or false.

Python Config generator
Our Python config generator script can be found in .circleci/scripts and is quite simple in principle. Its purpose is to stitch together different parts of our config together into a cohesive CircleCI configuration yml file called continuation-config.yml. It consumes several files as input:
parameters.json: As explained before, this file determines what projects should be added to the configuration file.config-template.yml: This is the base configuration file, which the Python script will read to add the jobs based on the parameters file.common-jobs.yml: It holds any job that may be conditionally added but is not part of a Connector build. In this case, it is only used forcore.connector-jobs.yml: It holds each specific application jobs, organised by the same keys as the parameters file
The Python script will read all these files and some additional inputs:
-d (Deploy): A boolean value to determine if deploy jobs should be added-e (External): A boolean value to determine if the build run should remove steps that will fail for external contributors, due to not having access to our secrets.
Continuation Jobs

Finally, we tell CircleCi to continue with the specified configuration, using their continuation/continue step, part of their circleci/continuation Orb (CircleCI’s way of creating reusable jobs).
The final result is our build pipeline:
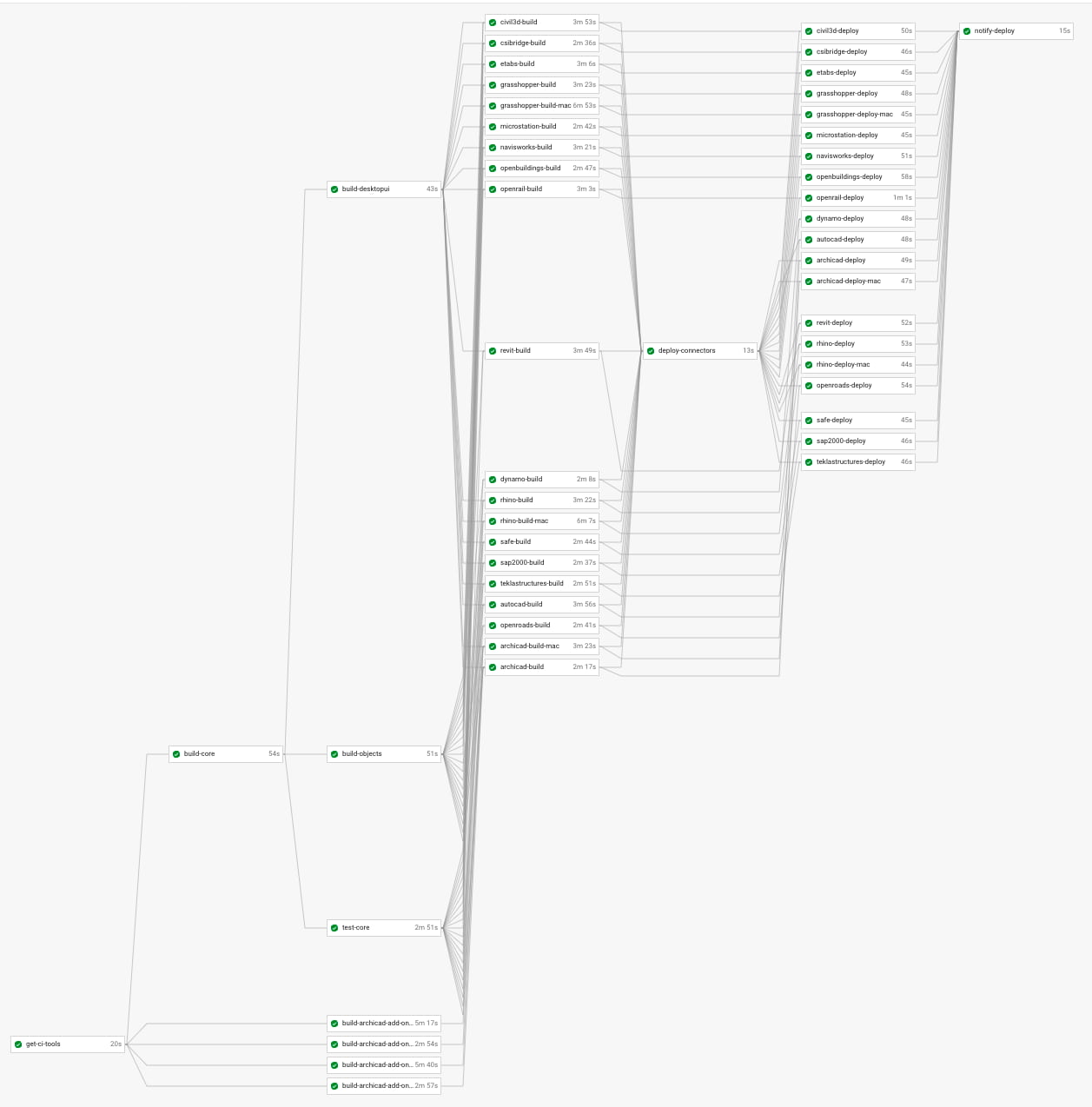
Pre-releases, releases, and hot-fixes
With our pipeline running and capable of pushing new versions of Speckle, we also have two categories of releases:
- Pre-releases: These can be
alpha,betaorrc(release candidate) depending on their level of maturity and the amount of testing that has been performed internally. i.e.2.13.0-alphaor2.13.0-rc1 - Stable releases: These versions are tested and in production-ready.
::: tip
Releases are automatically triggered when a new tag is created on the git repository, which is done by creating a new GitHub Release. This includes a basic auto-generated changelog based on a previously pushed tag.
:::
Both stable and pre-release versions can be installed through our Manager for Speckle application (available for Windows and Mac) which regularly polls the above-mentioned feeds for updates available to be installed.
What’s next?
Hopefully, this article shed light on our deployment strategy and has given you the inspiration to automate your software delivery processes.
There is always room for improvement, and as a matter of fact, we’re constantly improving and refining our pipelines to make them more resilient, flexible, and scalable - our final config file is currently nearly 1,500 lines of yaml 😰
We'll cover the publishing of our NuGet packages (a much easier task), testing, and other topics in future posts. Please do let us know what else you’d like to read in our Forum!