Schemas & Standards: The BYO Approach
Since the end of 2017, a few things have improved and changed in the way Speckle deals with object models and their implementation details in various CAD applications.
Written by Dimitrie Stefanescu on
Originally, Speckle embedded its own extensible object model and allowed for end-user defined data structures (classes) to pass through natively if the receiving party had access to original assembly. You can read more about this in this early blogpost.
This approach worked well so far, but due to the needs coming out from the community, many of which had existing object models, or were developing others internally, I have changed the architecture of how speckle deals with this aspect of interoperability to allow for more flexibility. Essentially, speckle has adopted a management solution to the wicked problem of AEC data interoperability.
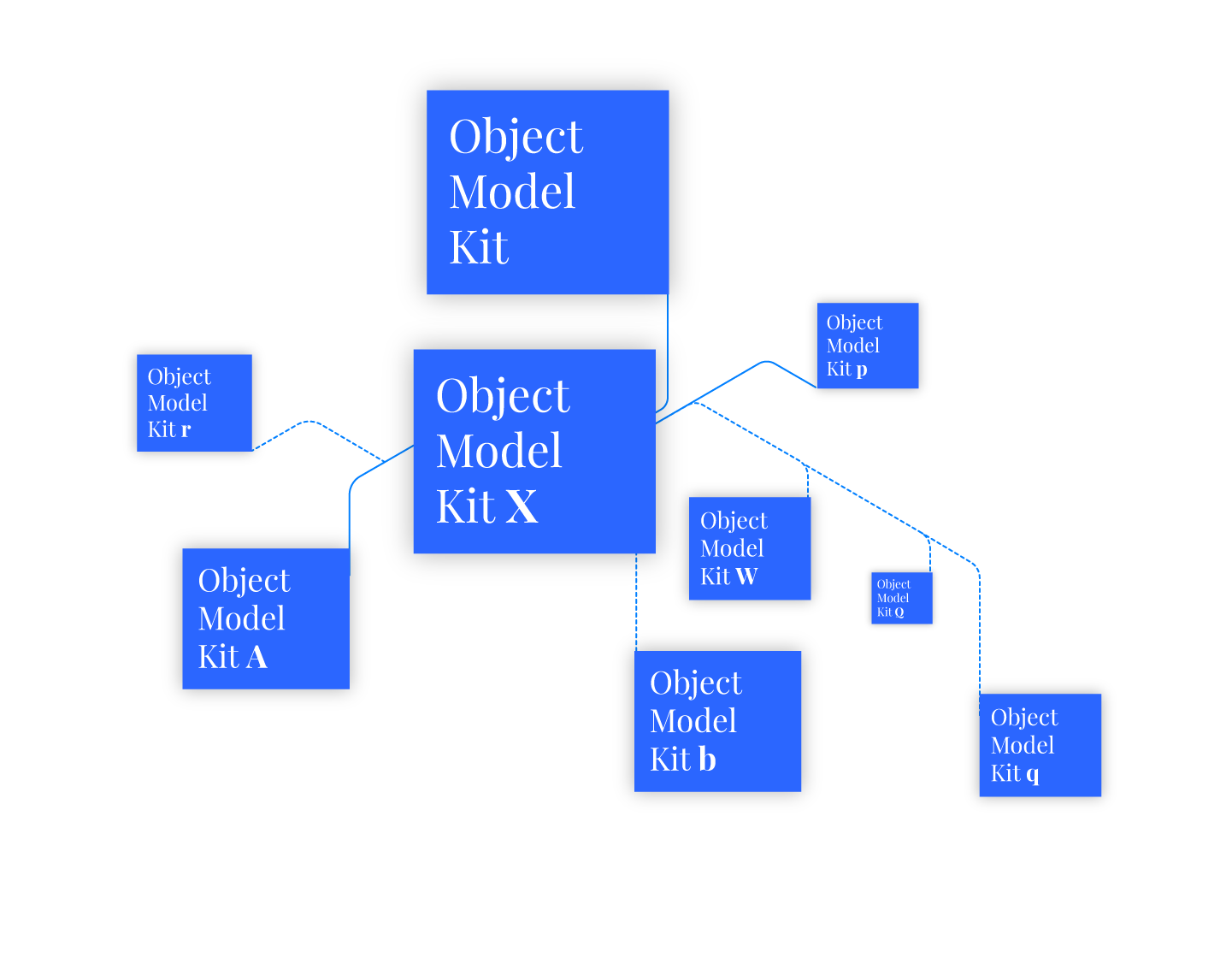
The big news is that you can fully replace speckle's "default" object model with your own, wrapped under a so called speckle kit. Essentially, it's now an officially "bring your own schema" party. Speckle only enforces minimal conventions to make sure speckle can still efficiently round trip objects and work its other magic. You can read more on how to create your own speckle-ready object model below:
Kits are a set of schema definitions coupled with a series of "implementations" in the software applications where they're relevant. They are dynamically loaded at runtime by speckle core, and they can build on top of each other. Furthermore, you can distribute them separately from the Speckle plugins themselves, and you have full rights to license and develop them as you see fit.
It's important to stress that interoperability in AEC is a wicked problem, involving a mixture of technical and political factors. While I strongly believe in the benefits a centralised, unified object model brings (such as the consistency associated with IFC), I also believe we need to allow for a process of bottom up evolution. Consequently, kits play several key roles:
- they enable an organic process of evolution of object models,
- they divide and conquer, ie they facilitate the subdivision of an immense problem into smaller, manageable, and hopefully crowd-sourced subsets, and
- they decouple schema from serialisation, allowing their independent evolution and development.
Feeback or comments? We'd love to hear from you in our community forum!
